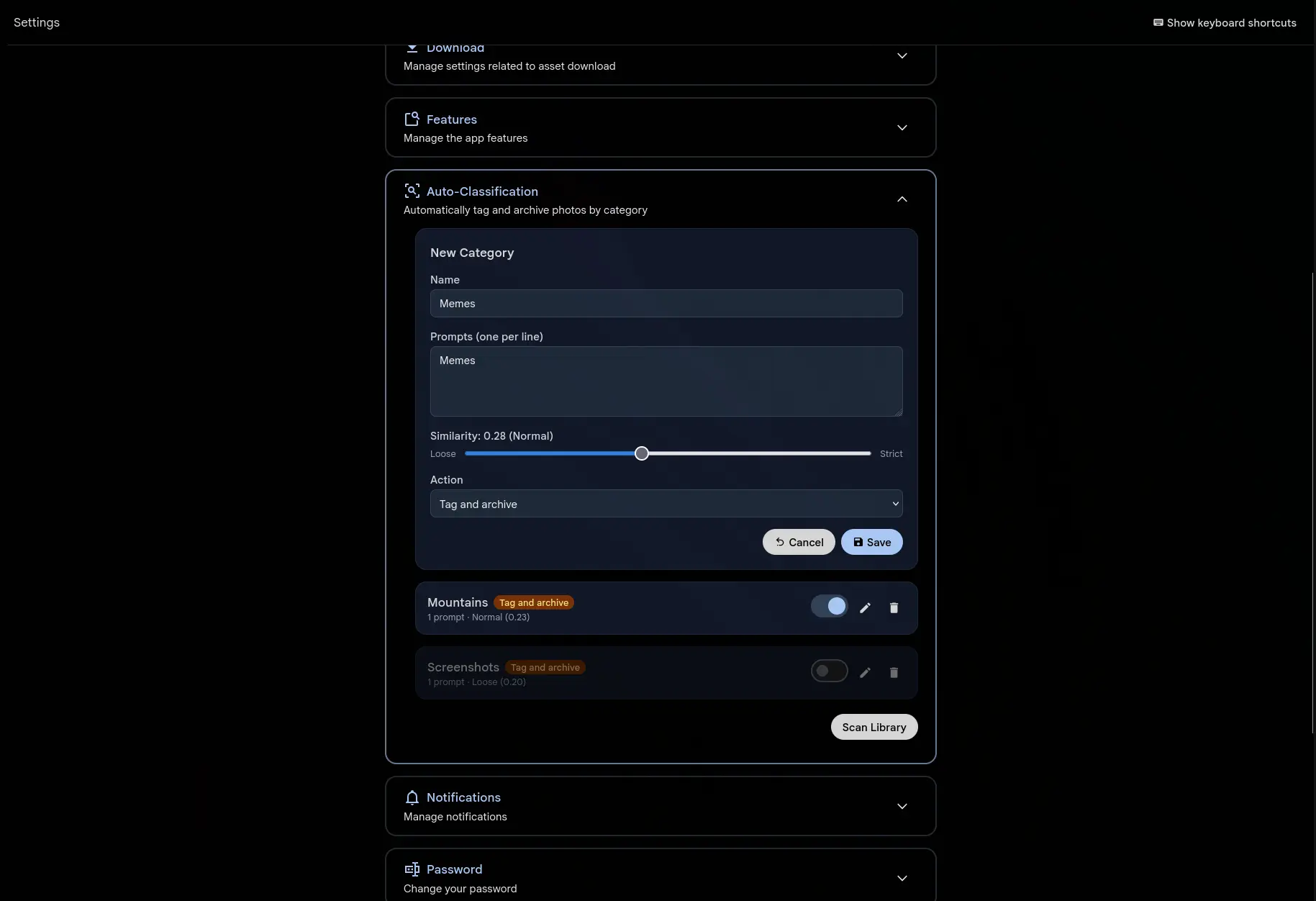
Vous décidez quelles catégories sont importantes. « Captures d'écran », « mèmes », « QR codes », « reçus » — tout ce qui encombre votre timeline. Pour chaque catégorie, vous rédigez un ou plusieurs prompts textuels décrivant ces images. Gallery utilise la même IA CLIP que la recherche intelligente pour comparer chaque photo à vos prompts.
Lorsqu'une photo correspond, elle reçoit automatiquement le tag Auto/NomDeLaCategorie. Si vous souhaitez également la faire disparaître de la timeline, définissez l'action sur « Tagger et archiver », et les photos correspondantes rejoindront discrètement l'archive. Aucune suppression, aucune perte de données — juste une vue plus épurée.
Fonctionne pour toutes les photos, anciennes et nouvelles
Les nouveaux imports sont classifiés dès que leur embedding CLIP est généré — dans le même flux qui alimente la recherche intelligente et la détection de doublons. Aucune étape supplémentaire, aucune attente.
Pour la bibliothèque existante, il suffit de lancer « Scanner la bibliothèque », et un job en arrière-plan classe tout. Des milliers de photos traitées en quelques secondes. La même file de jobs que vous utilisez déjà pour les miniatures et le transcodage.
Adapté à votre niveau de tolérance
Chaque catégorie possède son propre seuil de similarité. Déplacez-le vers « Permissif » pour obtenir plus de correspondances (avec davantage de faux positifs), ou vers « Strict » pour ne tagger que les correspondances très sûres. La valeur par défaut est bien calibrée pour la plupart des catégories.
Plusieurs prompts par catégorie améliorent la précision. Au lieu du seul terme « screenshot », vous pouvez ajouter « screenshot of a phone screen », « screenshot of a computer desktop », « screen capture with UI elements ». Plus de descriptions offrent à l'IA plus d'angles d'approche.
Géré par les administrateurs, efficace pour tous
Les catégories de classification sont configurées à l'échelle du système par les administrateurs sous Administration > Paramètres > Classification. Un ensemble de règles s'applique de manière cohérente à tous les utilisateurs — captures d'écran, reçus et mèmes sont traités de la même façon pour tout le monde. La bibliothèque reste ainsi propre sans que chaque utilisateur ait à gérer ses propres règles.
L'architecture est conçue pour évoluer : le classificateur actuel utilise la similarité texte-image CLIP, mais d'autres méthodes pourront être ajoutées ultérieurement — reconnaissance basée sur l'OCR, correspondance EXIF ou modèles dédiés — comme fonctionnalités distinctes.